
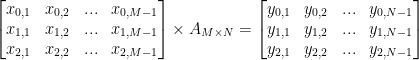

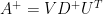

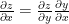
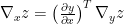






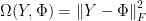
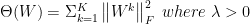
udara
Mathematics of Deep Learning
1 Introduction
Deep learning(DL) is becoming increasingly popular within machine learning community for wide range of applications like speech recognition [1], computer vision [2] and natural language processing [3]. The major advantage in DL is its ability to learn from raw input data. Traditional machine learning techniques require experts in a particular field to design feature extractors using domain knowledge. This requirement hindered the adoption of machine learning in many fields. DL does not suffer from this requirement, hence it is used in many unconventional fields like predicting activity of drug molecules, analyzing particle accelerator data and studying mutations in non-coding DNA on gene expression and disease [4].
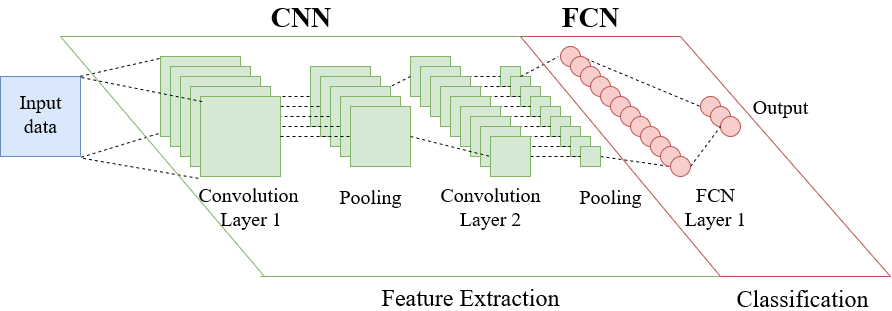
Figure 1: Architecture of Deep Learning Network
Architecture of a deep neural network(DNN) is shown in Fig 1. The DNN consist of two sub networks: convolution neural network(CNN) and fully connected network(FCN). The role of CNN is extracting features in spatially related input data. Multiple convolution layers are used to learn features with hierarchically increasing complexity. For example, if the input data is a raw input image first convolution layer would extract low level features like horizontal and vertical edges. Next convolution layer learns mid level features like motifs created by combination of local edges. Motifs assemble high level features like different parts of objects. Feature extraction is done by applying convolution operator(1) on input data. Rectified linear unit(ReLU) is often used as the activation function for convolution layers. In addition to low computing complexity, ReLu usually learns faster in networks with many layers [4]. Max pooling or mean pooling operation is performed to reduce the input data size. Convolution neural network(CNN) is followed by a fully connected network(FCN) for performing classification. Non-linear functions like sigmoid are preferred as the activation function for FCN. Non-linear activation function maps the input data to a linearly separable space which provides better classification results.
DL has shown superior performance compared to other networks. AlexNet [2] was able to achieve top-5 error rate of 17.0% in ImageNet LSVRC-2010 contest outperforming other solutions by a significant margin. DNNs were able to reduce word error rates in speech recognition by 30% over conventional techniques [5]. Although efficiency of DL is seen empirically, the mathematical reasoning for its performance remains elusive [6]. This report presents the mathematical model of DL which is useful in understanding the operation of DL.
2 Preliminaries
2.1 Solving linear systems
A linear system can be represented by a matrix. The output (y) of the system is given by the multiplication of system matrix (A) and input vector (x). Matrix inversion can be used to find the input when the output and system is known. The problem of interest in DL is finding the system when input and output is known. This problem can be solved using a collection of inputs and outputs. For this lesson we will use the convention of using rows to represent individual inputs and outputs where an element in a row represents a dimension (a feature in ML) of the input/output. The system matrix has the shape of 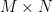
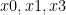

In order to model the system,
2.2 Gradient Descent
In order to solve the linear(or nonlinear) system using numerical computing, problem is redefined as an optimization problem. Optimization algorithms iteratively search parameter values that minimize a function output. The function that is being minimized is called objective or loss function. An example of a loss function is the square of Euclidean distance between 
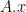

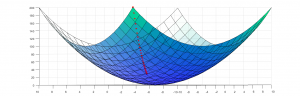
Figure 2: Application of gradient descent algorithm on a loss function
2.3 Back Propagation
Numerical computing methods like gradient descent and its variants require the gradient of a multi dimentional function. This task is accomplished by back propagation algorithm which is an efficient way of computing chain rule of calculus, with a specific order of operation. The chain rule is shown below which can extended to 

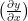

Mathematics of Backpropagation
This explanation is from book chapter : Neural networks and deep learning chapter 2
All methods that are used for training (GDA, SGC) require calculating the gradient of the cost function w.r.t weights and biases. We use the back propagation to make this computation.
The output activation of layer l can be written as follows where sigma is the non-linear activation function
|
alternatively using weighted input
 |
As a common cost function let’s use quadratic cost function
 |
- Two assumption are made on the choice of cost function
- The overall cost is the average of the cost for individual inputs
- The cost can be calculated using output activations
The goal of back propagation is calculating following entities
 |
To achieve the goal let’s first calculate an intermediate term: Change of cost w.r.t weighted input
|
|
Gradient of the cost function w.r.t activation for the output layer(L) (assuming quadratic cost function take the derivative w.r.t activation a) and hidden layers can be written as
|
|
By putting everything together we can write the partial derivative of the cost function as follows. Here to obtain the value w.r.t to biases and weights from the respective delta value we use the simple chain rule

2.4 Bernoulli and Multinoulli Distribution
Deep learning is widely used for object classification. A neural network that classifies input to 
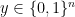

3 Mathematical Model of Deep Learning
3.1 Inference Model
The mathematical model for inference in a DNN can be written as below where 

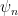




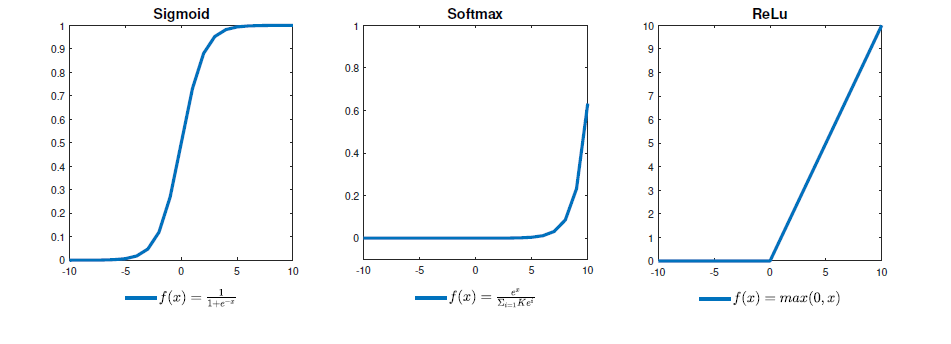
Figure 3: Widely used activation functions
The hierarchical structure of DNN is made possible by the use of non-linear activation function. If activation function is not present all layers can be replaced by a single layer. In the first generation neural networks (perceptrons), threshold function is used as the activation function. It has been shown that perceptron is a universal digital function approximator. The second generation neural networks prefer sigmoid activation function because they can approximate any continuous function. However sigmoid activation has low learning performance because the gradient decay to zero quickly. The modern DNN widely use ReLu for convolution layers and Softmax for fully connected layers.
3.2 Training Model
Training of neural networks refer to finding the optimum weight parameters. However learning algorithms differ from optimizing algorithms because the primary goal of learning is to predict the output for unseen data which require avoiding overfitting to training data. Below equation shows the mathematical representation of learning problem. According to our convention each row of 


In the above equation, 
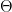

In order to minimize loss function numerical computing methods like gradient descend algorithm is used. However most learning algorithms are typically guarantee to converge to a critical point. Figure below shows different critical points present in non convex functions. Although there is no rigorous proof, experimental results suggests that when network size is large enough and ReLu activation is used all local minima could be global [7].
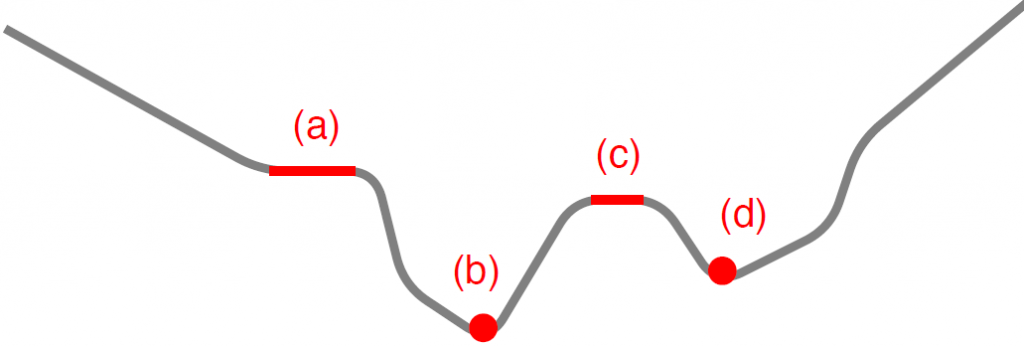
(a) saddle point, (b) global minima, (c) plateau, (d) local minima
4 Summary
This report discusses the mathematical aspect of deep learning as an attempt to understand its superior performance. Deep learning does not depend on input or output data types hence the technique can be applied in many fields. Recent advancements in deep learning have introduced several techniques to improve the performance of generic implementation. Techniques like pooling has improved the numerical stability of the system. The introduction or ReLu activation function has resolved the local minima problem because of the global optimality in positive homogenous networks. The development of hardware and optimization has accelerated adoption of deep learning. With continuous success in variety of fields, deep learning is becoming a dominating technology in future applications.
Reference
[4] Yann LeCun, Yoshua Bengio, and Geoffrey Hinton, “Deep learning,” Nature, 2015.
[6] Rene Vidal, Joan Bruna, Raja Giryes, and Stefano Soatto, “Mathematics of deep learning,” 2017.
[7] Ian Goodfellow, Yoshua Bengio, and Aaron Courville, Deep Learning, 2016
[8] Kevin Murphy, Machine Learning: A Probabilistic Perspective, 2012.

Leave a Reply